

Serverless Framework & Lambda: A Match Made in Heaven
31 May 2016Serverless HipChat Connect Boilerplate by GorillaStack
30 Jun 2016We are strong advocates of the Serverless framework at GorillaStack. We’ve recently talked about our recent open source Serverless HipChat Connect example that utilizes Serverless and AWS Lambda. During the development of the plugin, one thing we liked was that Serverless doesn’t restrict you to one architecture – there are at least 4 serverless architectures to choose from.
1. The Monolith
Whenever I hear “monolith”, I think of a massive LAMP project with a single, burning hot MySQL database.
(not always the case). The monolith architecture looks something like this in Serverless:
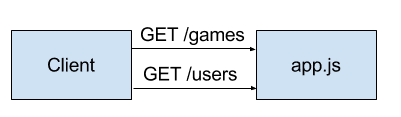
I.e. all requests to go to a single Lambda function, app.js. Users and games have nothing to do with one another but the application logic for users and games are in the same Lambda function.
Pros
We found that the greatest advantage that the monolith had over nanoservices and microservices was speed of deployment. With nanoservices and microservices, you have to deploy multiple copies of dependent node_modules (with Node.js) and any library code that your functions share which can be slow. With the monolith, it’s a single function deployment to all API endpoints so deployment is faster. On the other hand, how common is it to want to deploy all endpoints…
Cons
This architecture in Serverless has similar drawbacks to the monolithic architecture in general:
- Tighter coupling. In the example above,
app.jsis responsible for both users and games. If a bug gets introduced into the users part of the function, it’s more likely that the games part might break too - Complexity. If all application logic is in a single function, the function can get more complicated which can slow down development and make it easier to introduce bugs.
2. Microservices
Microservices in serverless architecture looks something like this:
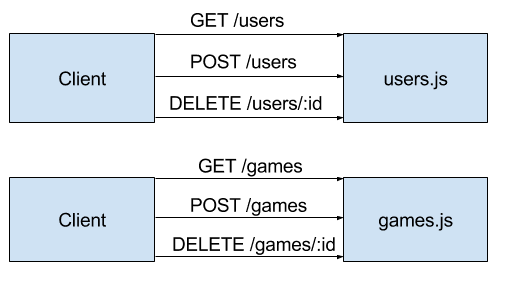
Pros
The advantages of the microservices architecture in Serverless inherits advantages of microservices in general. A couple:
- Separation of concerns. If a bug has been introduced into
games.js, calls tousers.jsshould carry on working. Of course, maybe GET /users/:id might contact the games microservice to get games that the user plays but ifusers.jsandgames.jsare proper microservices thenusers.jsshould handlegames.jsfailing and vice versa - Less complexity. Adding additional functionality to
games.jsdoesn’t make theusers.jscodebase any more complicated
Cons
As mentioned above with the monolith, microservices in Serverless can result in slower deployments.
3. Nanoservices
Nanoservices take microservices to the extreme – one function per endpoint instead of one per resource:
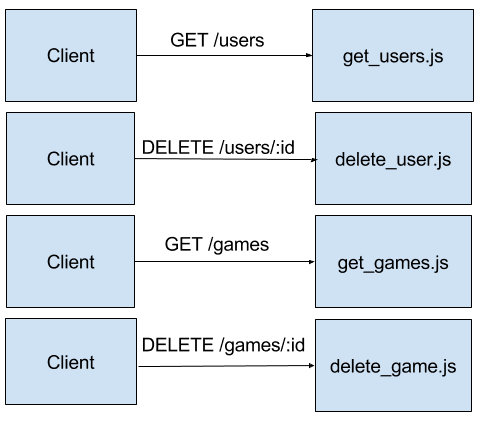
Pros
Nanoservices take the advantages of microservices and amplifies them. Separation of concerns is greater – get_users.js is probably going to be simpler than users.js that handles everything to do with a user.
Cons
Again, similar to microservices but even more so – the number of functions to deploy can get huge so deployment time can increase.
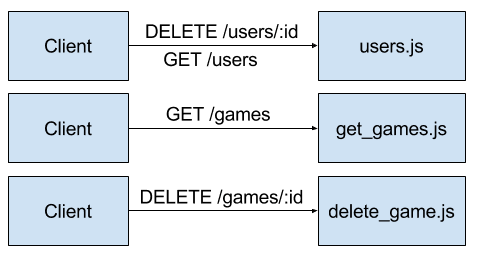
4. Hybrid
There is nothing to stop Developers taking a hybrid approach to their serverless architectures e.g. a mixture of nanoservices and microservices. In our example, if there was a lot of game functionality, it might make sense to split the functionality into nanoservices but if is less functionality related to users, microservices could be more appropriate:
If you have any examples of how you’re architecting your Serverless projects, tell us about it!



{kind=link}
{kind=link}
{kind=link}