
GorillaStack launches Insights for Amazon Web Services
27 Apr 2016GorillaStack Auto Tag Gets An Update
09 May 2016
We were excited to have the opportunity to share GorillaStack with everyone at Sydney’s first 2 day AWS Summit. The Summit demonstrated the need for AWS Cost Optimization. Talks such as “Business: Cost Optimization at Scale” from Evan Crawford at Amazon Web Services amplified this customer demand.

And yes, that is gorillas.bas running in the background (check out our version of gorillas.bas on GitHub).
Between talking to customers about Insights, our new AWS Rightsizing product at the GorillaStack booth, we attended some great talks on microservices and going “serverless” – here are 8 things we learned.
There is more than one Microservices architecture
“No Server Is Easier To Manage Than No Server” Werner Vogels, CTO, Amazon.com
Source: re:invent on Twitter (re:invent 2015). Quoted at Sydney Summit 2016 more than once.
You might consider the nirvana of microservices on AWS to be a completely serverless architecture using products such as API Gateway and Lambda. In reality, most customers don’t seem to be in this paradise yet. When Craig Dickson, Solutions Architect from Amazon Web Services asked the audience “who’s running a completely serverless architecture?”, I only saw one hand go up. If you currently have a monolithic architecture, it might be a bigger step moving to a serverless architecture than it would be to break your monolith down into a solution with instances and containers. You might also have a microservices architecture that combines serverless and non-serverless solutions.
Microservices will change your Development Processes
MYOB talked about how their Development Team has completely changed since moving to microservices.
A sprint team at MYOB takes responsibility for a microservice if they have built the service. If another team needs the service to be changed, change should be accommodated into the sprint belonging to the team that is responsible. If the change is too big for the team to accommodate, the service responsibility is transferred to the other team.
Automate EVERYTHING
With microservices, if things are not automated quickly then a lot of wasted time tends to accumulate. Real world example: If database migrations don’t run as part of your deployment process for your monolithic application then it might have been excusable. It’s little effort to manually run the migrations. With microservices, if you have many services written in multiple languages and frameworks, it starts to become more laborious to remember how that particular service’s migrations are meant to execute.
Some upfront effort to automate early can pay dividends in the future.
Microservices should be micro
Amazon have said a microservice is something that “could be rewritten in two weeks”.
Pizza teams
Teams working on microservices should be micro too. “Two pizzas should be able to feed a team” (not sure if I agree with this.. I can eat quite a lot of pizza).
You can find more information on the last two lessons from the deck on SlideShare.
Don’t look down on the monolith
Microservices incur a development overhead – if you’re an early stage startup then it’s probably more important to get your product in front of VCs fast. Your Development team probably finds the lambda function that maintains one of your AWS security groups cooler than the venture capitalist thinks it is.
Your API gateway could be a monolith
It’s great having this super scalable microservices architecture but if the whole thing is behind a single API gateway then isn’t the API gateway a monolith itself? Amazon Web Services suggested the idea of having multiple API gateways e.g. api.gorillastack.com, insights-api.gorillastack.com, beta-api.gorillastack.com.
Your architecture needs to be resilient to microservices going down
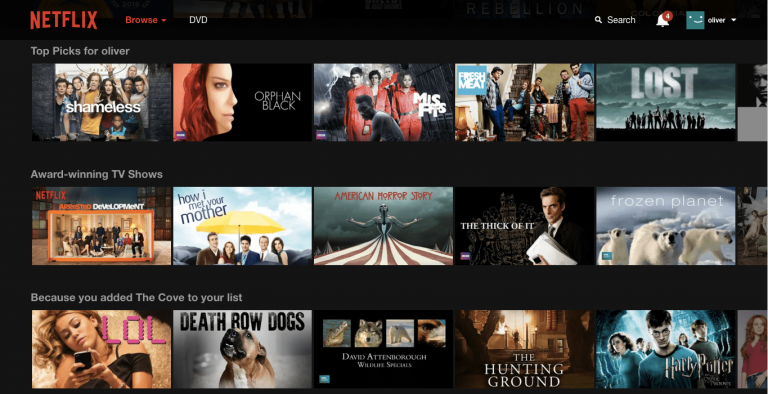
Craig Dickson, Solutions Architect from Amazon Web Services used Netflix as an example of how this should work. “Top Picks” is based on Netflix’s Recommender System. Let’s assume for argument’s sake that the recommender system is a single microservice. If the recommender microservice goes down then “Top Picks for Oliver” should be computed with some fallback algorithm e.g. “most watched”. Netflix shouldn’t be interrupted just because the recommender system broke.



{kind=link}
{kind=link}
{kind=link}